
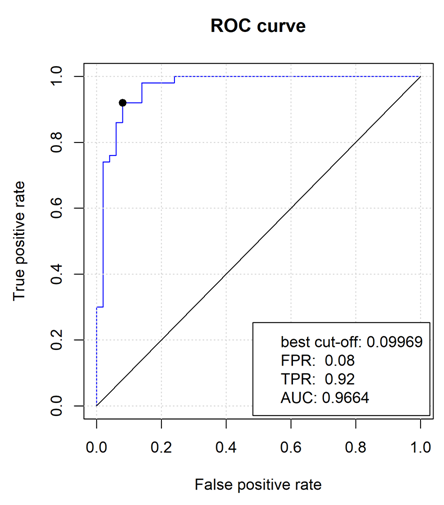

选用了目前主流的分类器(比如 SVM,KNN)以及筛选特征值的方法(贪婪算法)筛选并建立稳定的模型,帮助客户筛选到灵敏度与特异性高的 maker。
分子建模预测
采用模式识别与数据挖掘技术有效进行模型的构建,将部分数据拿来做训练集预测模型,然后部分数据作为测试数据集(独立样本)来验证模型的准确性。目的在于利用实验数据来筛选出一批靶标基因,并以此构建模型。小样本数据的建模在于筛选并评判 maker 的稳定性,便于后期实验验证;大样本数据的建模用于进行早期诊断、疾病预测。采用方法分为:线性分类器以及非线性分类器,并利用了 Leave-one-out cross-validation(LOOCV)以及 cross-validated misclassification error rate 的筛选策略找到优选 MARKER。

1、小样本建模:样本数在 20 以上;
2、大样本建模:样本数在 100 以上;
3、数据类型:表达,甲基化,CNV,SNP 均可。

1、图片格式:ROC 曲线图,TIFF 格式;
2、文本文件:样本的分类情况,灵敏度与特异性,maker 的权重(线性分类器结果)。
-END-

